关于Python程序模块化
Python提供了functions,modules,packages和classes作为模块化程序的工具。
Function
docstring是一种出现在模块、函数、类或者方法定义的第一行说明的字符串,这种docstring就会作为该对象的__docs__属性。它形如
1
2
3def kos_root():
"""Optional Function Description (Docstring)"""
... FUNCTION CODE ...
函数返回值时如果用逗号分开多个返回值,python会自动把它们打包为一个tuple。
没有返回值的函数叫做void function,返回None。
positional argument按函数定义中参数顺序传参,不需要参数命名。keyword
arguments通过kwarg=value传参。keyword
arguments需在positional argument后。
在函数中修改不可变参数(如number,string)不影响调用函数的原程序(calling program)中传入函数的变量的值,而原程序中可变参数(如list)则会跟着改变。
使用形如def name(arg1=default_value, ... ):的句子可以为参数设置默认值,这样的参数称为默认参数(default
parameters),调用函数时可以不给。一般来讲默认参数定义在函数参数末尾处。
可变参数(arbitrary
argument)可以让你传入多个参数。*args允许函数接收任意数量的位置参数,这些参数会被打包成一个tuple,**kwargs则用于接收任意数量的关键字参数,这些参数会被打包成一个字典。。*args必须在positional
argument之后,而**kwargs必须在最右。参数命名不一定非要用args和kwargs,但这是约定俗成的命名。
python程序可从命令行(command
line)中接受任意多参数。import sys以接受这些参数,sys.argv是这些参数被打包而成的string的list(如控制台输入python a b c则sys.argv为['a',
'b', 'c']。
python程序中可以用global关键词使全局变量可以在函数中被修改。
lambda表达式是python中可用的内嵌(in-line)函数,它形如lambda arg1, arg2, ... : expression。
filter(function, iterable)函数用于过滤可迭代对象,过滤掉不符合条件的元素,返回由符合条件元素组成的新可迭代对象。function为判断函数,返回True或False。
map(function, iterable, *iterables)返回一个可迭代对象,由function分别应用在可迭代对象iterable每一项得到。如果传递了额外的可迭代对象参数,则函数必须接受相同数量的参数,并并行应用于所有可迭代对象中的项。对于多个可迭代对象,迭代器在最短的可迭代对象耗尽时停止。
Module
模块(Module)是是包含Python定义和语句的文件。文件名是模块名加上.py后缀,模块中的定义可以导入到其他模块或主模块中。在模块中,模块的命名(作为字符串)可以作为全局变量__name__的值使用。模块有一个包含任意Python对象的命名空间。模块通过import过程加载到Python中。
例如一个名为fibo.py的文件可以通过import fibo导入为模块。假若它具有以下内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# Fibonacci numbers module
def fib(n): # write Fibonacci series up to n
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
print()
def fib2(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while a < n:
result.append(a)
a, b = b, a+b
return result
那么运行
1
2
3
4
5
6fibo.fib(1000)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
fibo.fib2(100)
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
fibo.__name__
'fibo'
类似地可以给模块中函数赋一个本地命名
1
2
3fib = fibo.fib
fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
模块可以包含可执行语句及函数定义。这些语句用于初始化模块。它们只在import语句中第一次遇到模块名时执行。事实上,函数定义也是被“执行”的“语句”;模块中函数定义的执行将函数名添加到模块的全局命名空间中。(如果文件作为脚本执行,也会运行它们)。
每个模块都有自己的私有命名空间,它是模块中定义函数的全局命名空间。使用modname.itemname可以调用模块的全局变量。
可以直接导入模块中的命名到当前调用这个模块的命名空间,例如
1
2
3from fibo import fib, fib2
fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
import将整个模块作为一个对象导入到当前命名空间中,不会导致命名的混淆。而from
… import则有可能导致命名的混淆。
而形如from fibo import *的句子则可以导入模块中全部不以_开头的命名。它有可能覆盖主程序中此前定义的命名,因而会有风险。
import后加as可以将一个新命名绑定到被导入模块命名,如import fibo as fib。
每个模块在每个解释器会话中只导入一次。
内置函数dir()用于查找模块定义了哪些名称。它返回全部模块中定义的名称对应字符串组成的列表。
Python有内置的help函数。调用内置的帮助系统。(此功能仅供交互使用。)如果没有给出参数,交互式帮助系统将在解释器控制台上启动。如果参数是字符串,则将该字符串作为模块、函数、类、方法、关键字或文档主题的名称进行查找,并在控制台上打印帮助页。如果参数是任何其他类型的对象,则生成该对象的帮助页面。
Package
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的
Python 的应用环境。简单来说,包就是文件夹,但该文件夹下必须存在
__init__.py 文件,该文件的内容可以为空。
__init__.py
用于标识当前文件夹是一个包。这可以防止具有公共名称(如string)的目录无意中隐藏稍后在模块搜索路径上出现的有效模块。在最简单的情况下,
__init__.py
可以只是一个空文件,但它也可以执行包的初始化代码或设置
__all__ 变量。
包是通过使用“带点的模块名”来构建Python模块命名空间的一种方式。例如,模块名A.B在一个名为a的包中指定了一个名为B的子模块。就像使用模块可以使不同模块的作者不必担心彼此的全局变量名一样,使用带点的模块名可以使NumPy或Pillow等多模块包的作者不必担心彼此的模块名。
可以从包中导入单个模块,如import sound.effects.echo。
模块中的代码也可以当作脚本被执行,就像导入它时一样,但__name__设置为__main__。
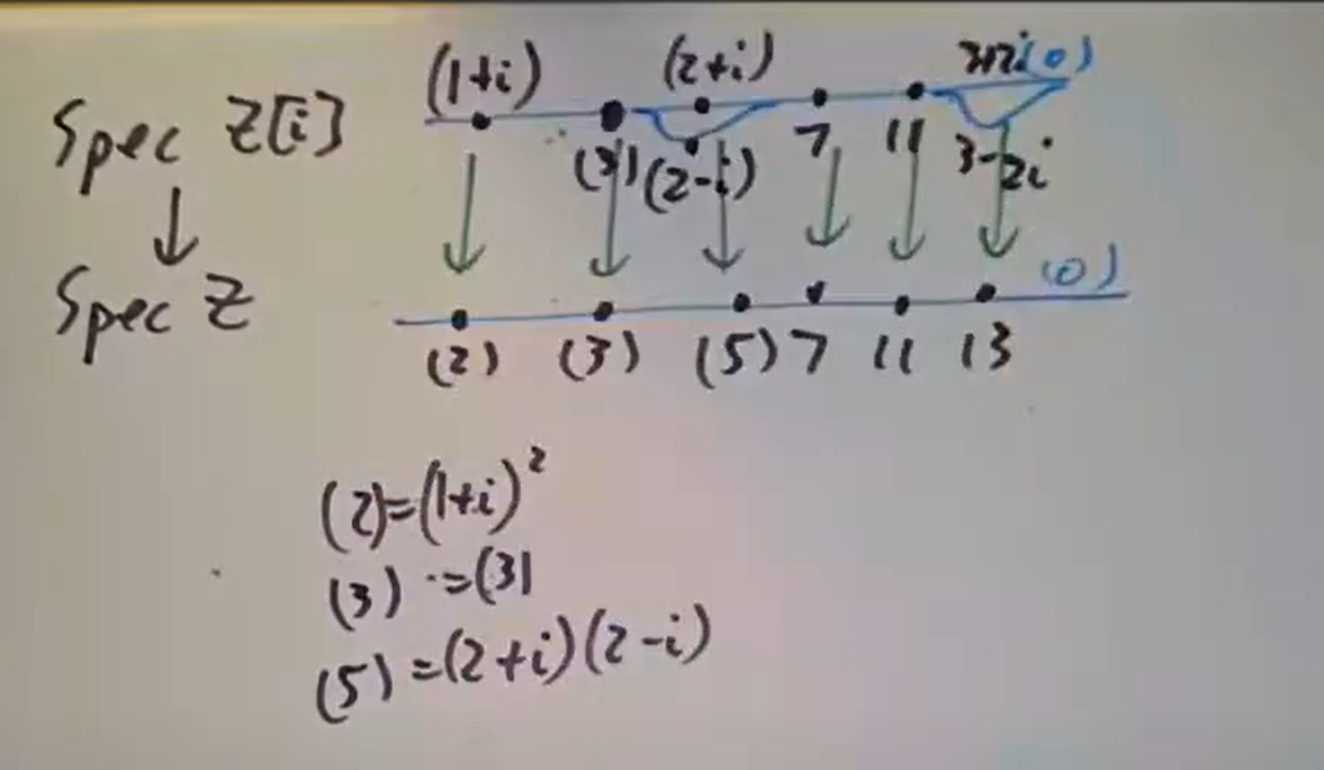
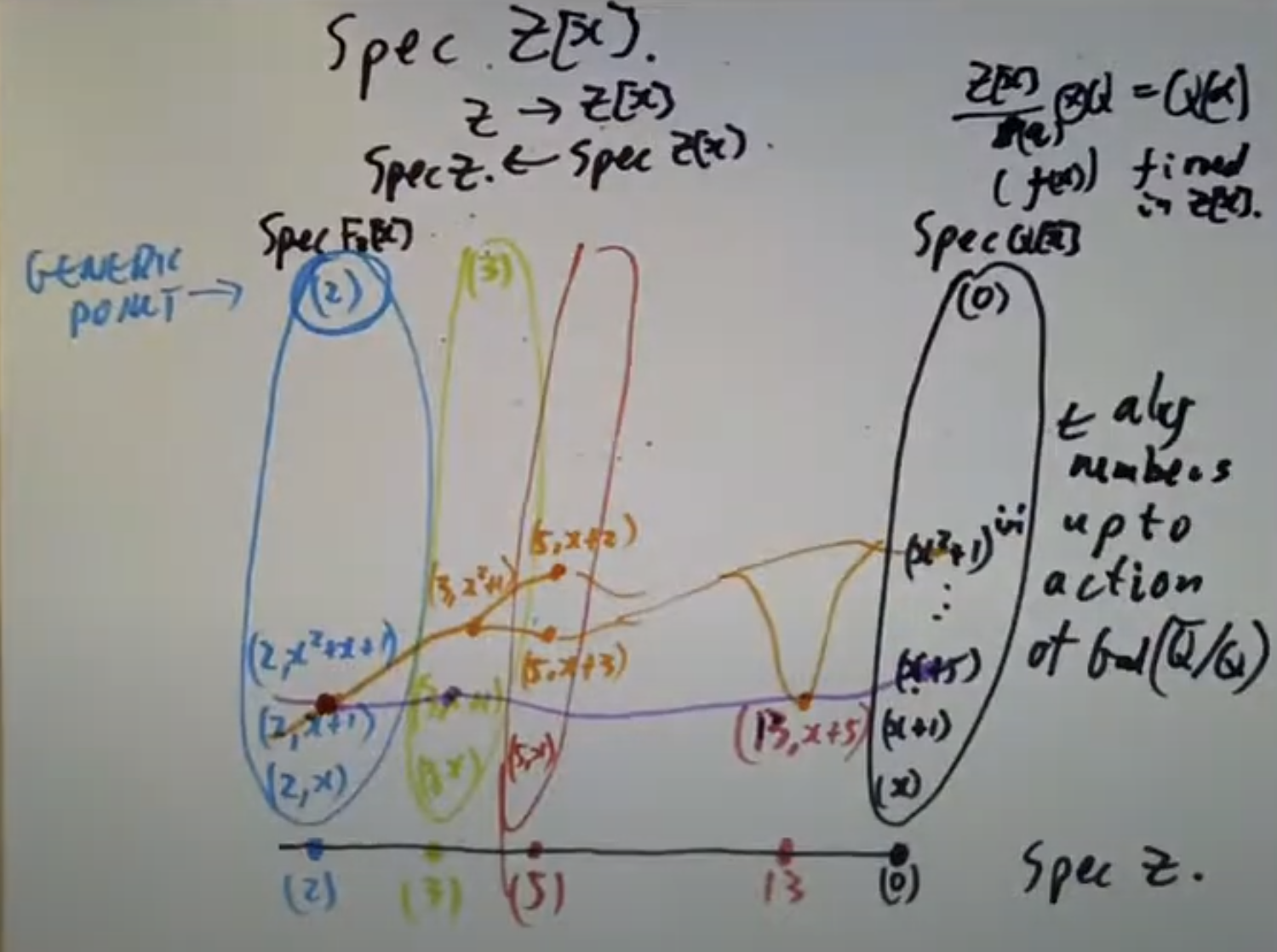
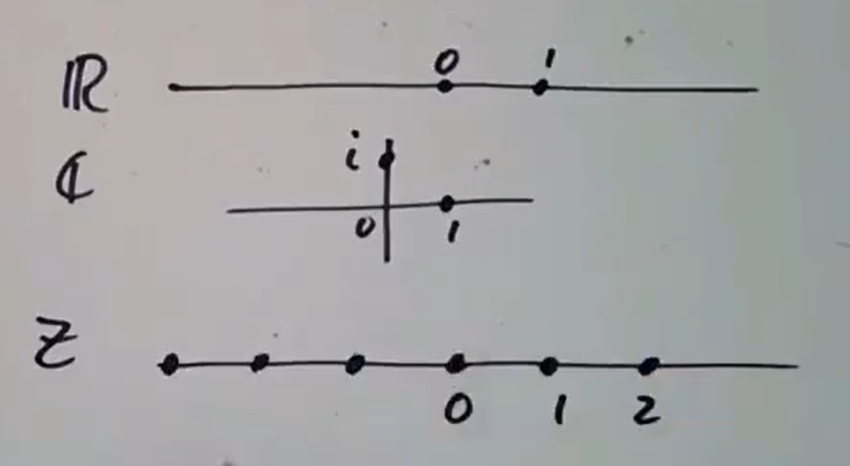 此外有高斯整数
此外有高斯整数  这种可视化手段的一个直接应用是:
这种可视化手段的一个直接应用是: 则立即可知上述
则立即可知上述 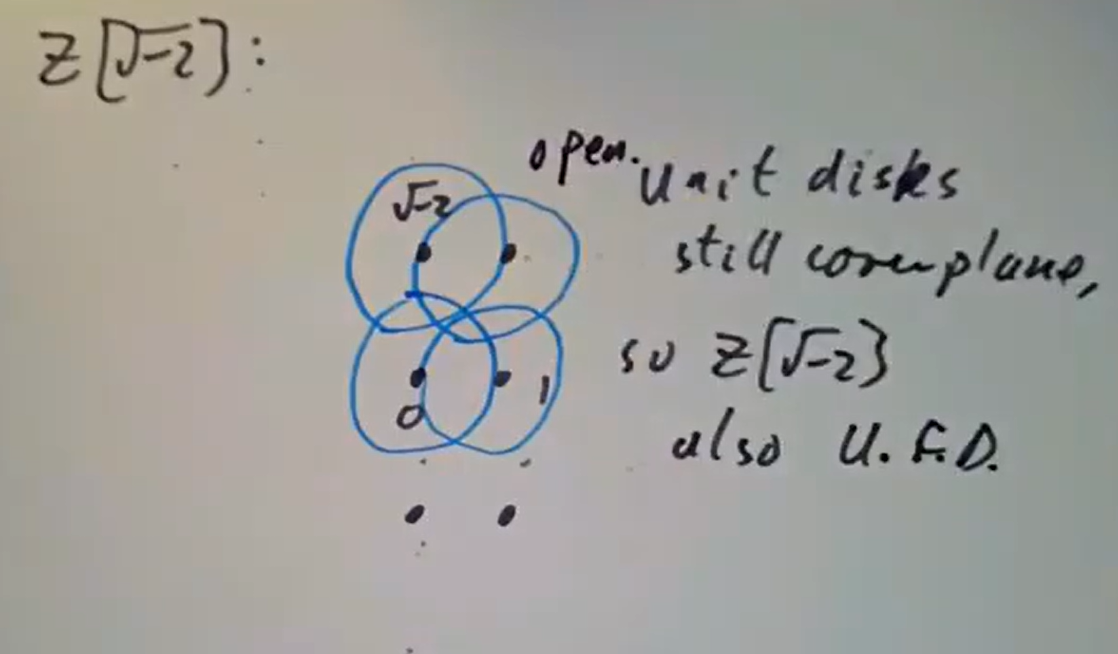 画图立即可知。
画图立即可知。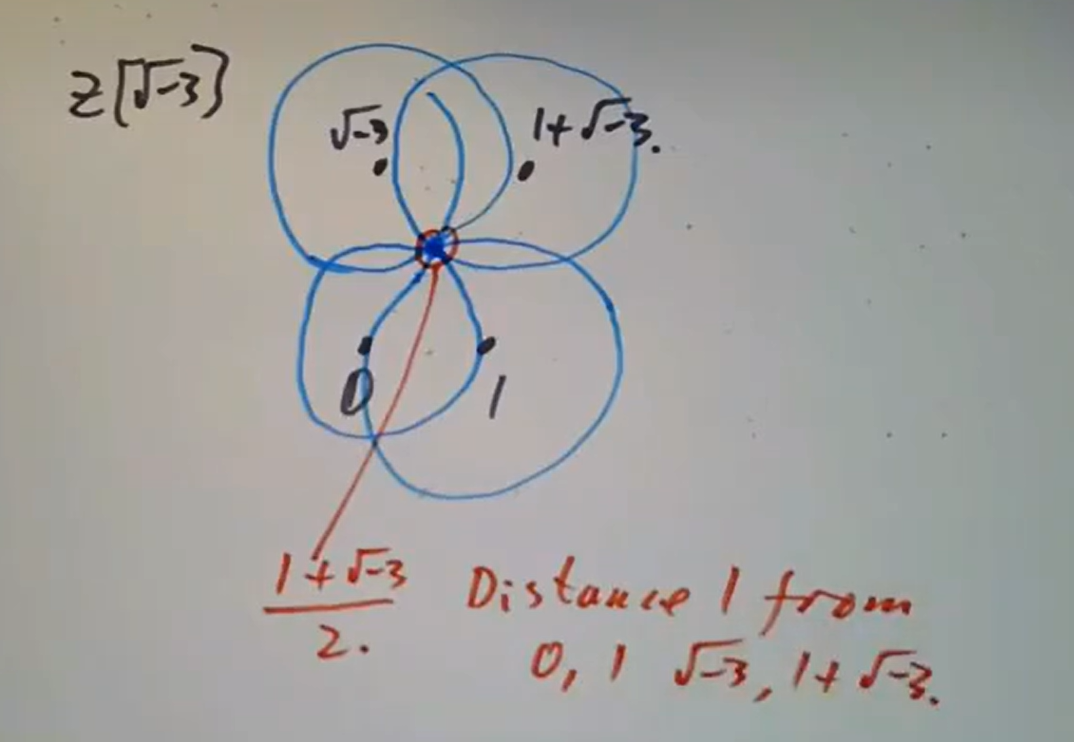 非但如此,
非但如此,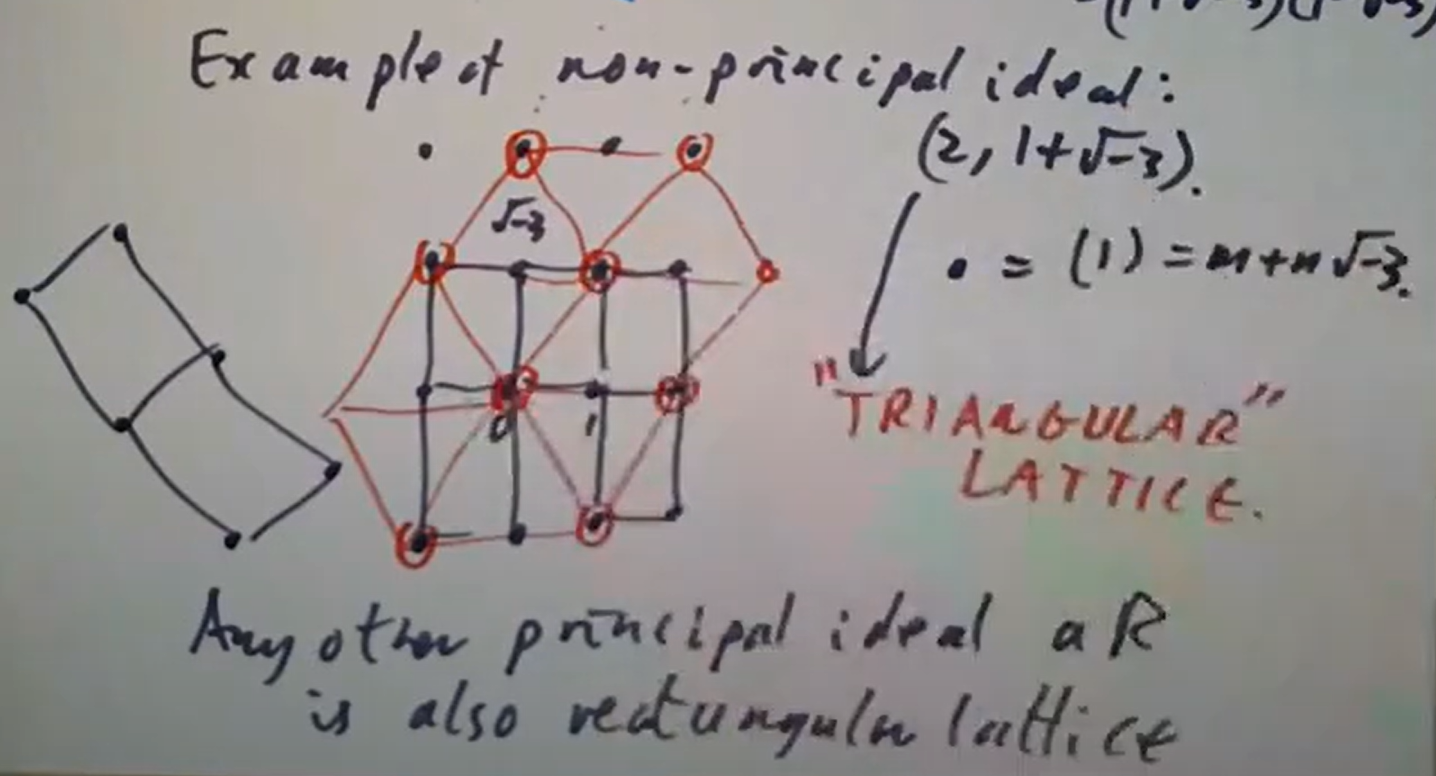 这里
这里 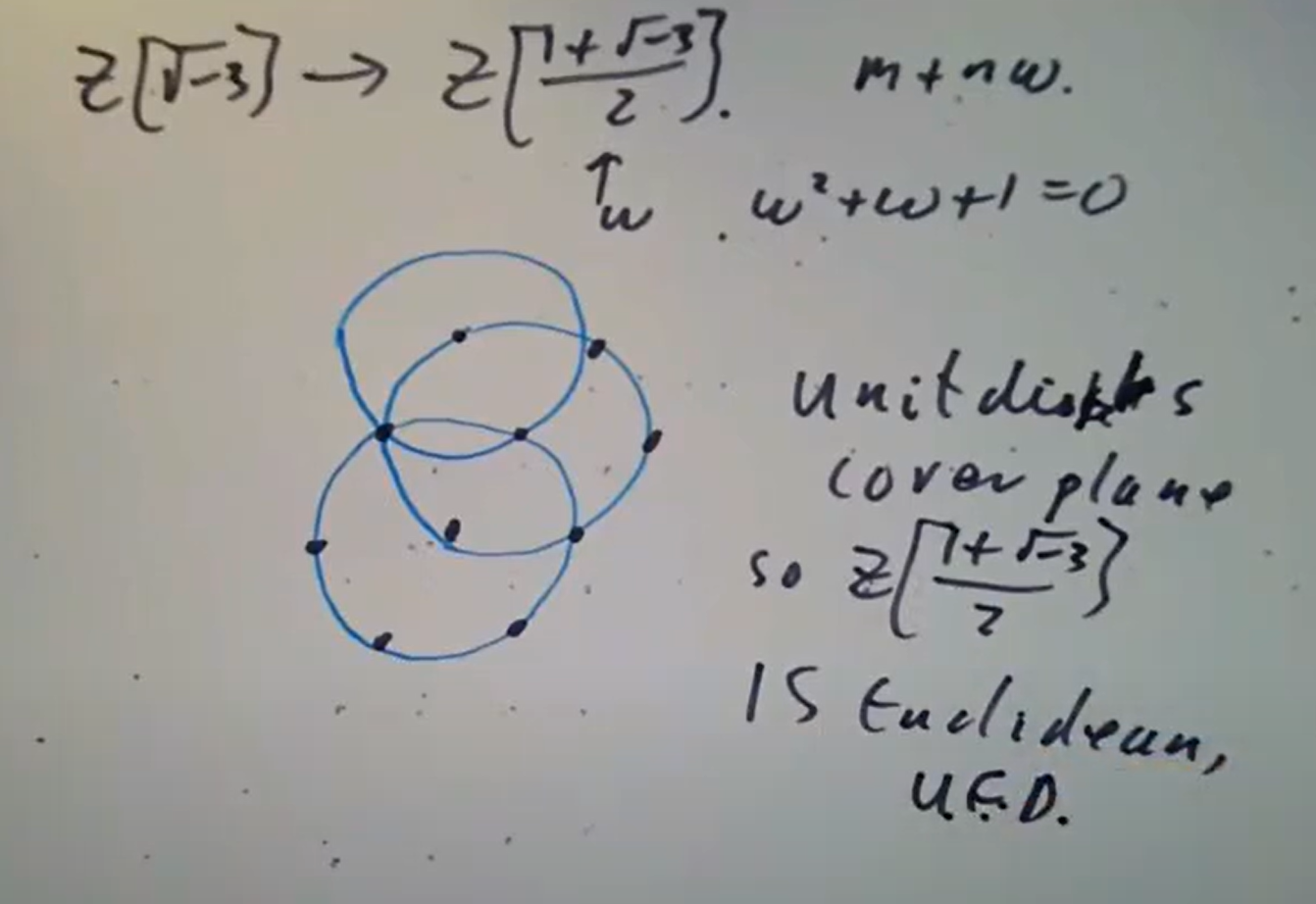
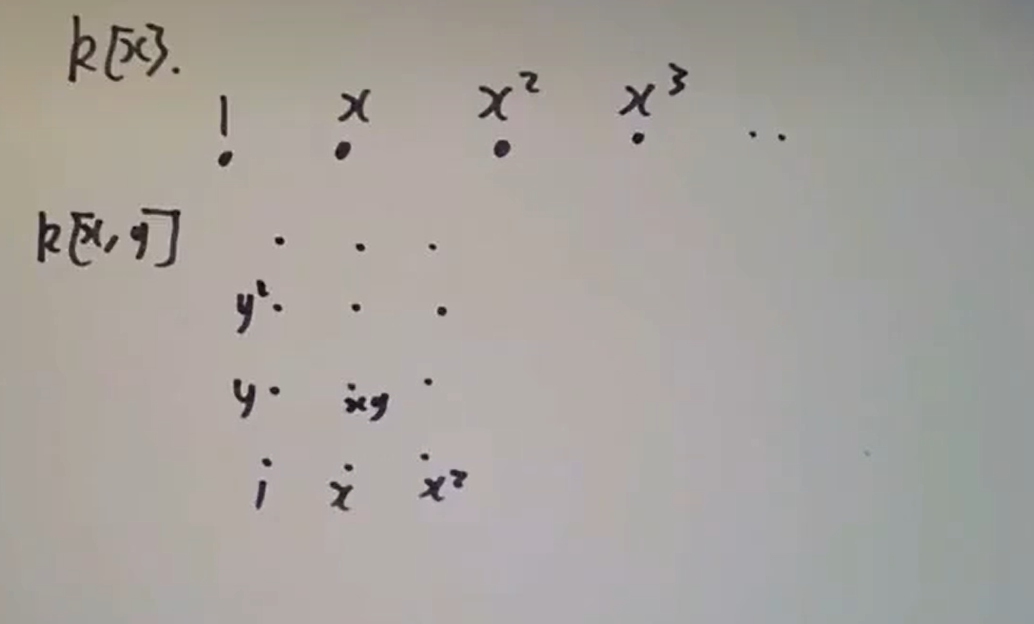
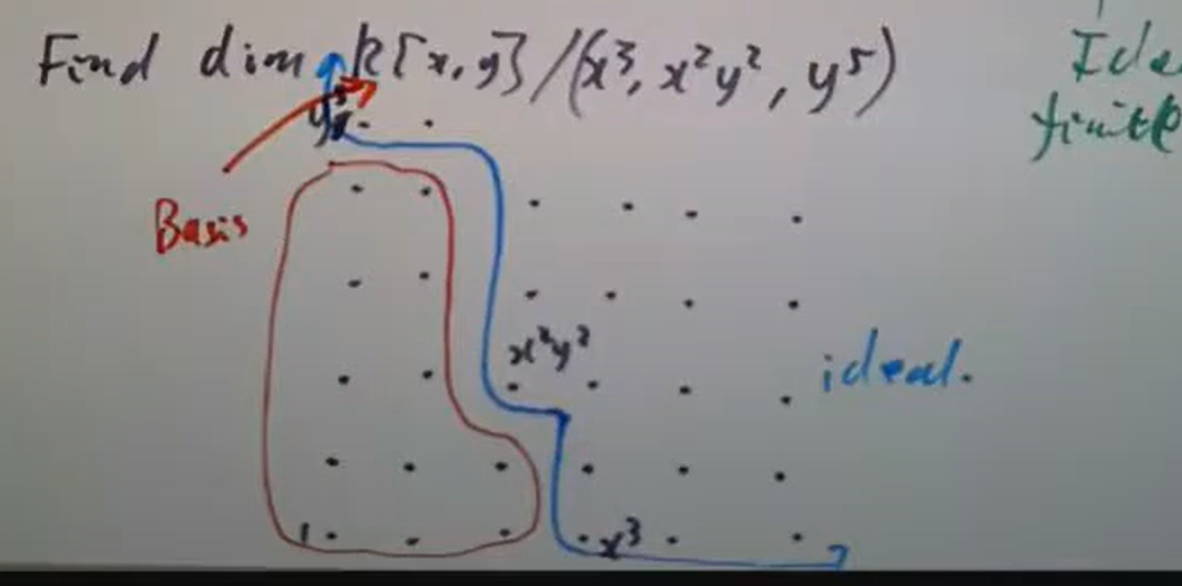 红圈中的元素便给出商环的一组基,于是立即可知
红圈中的元素便给出商环的一组基,于是立即可知  注意到不变量环同构于
注意到不变量环同构于 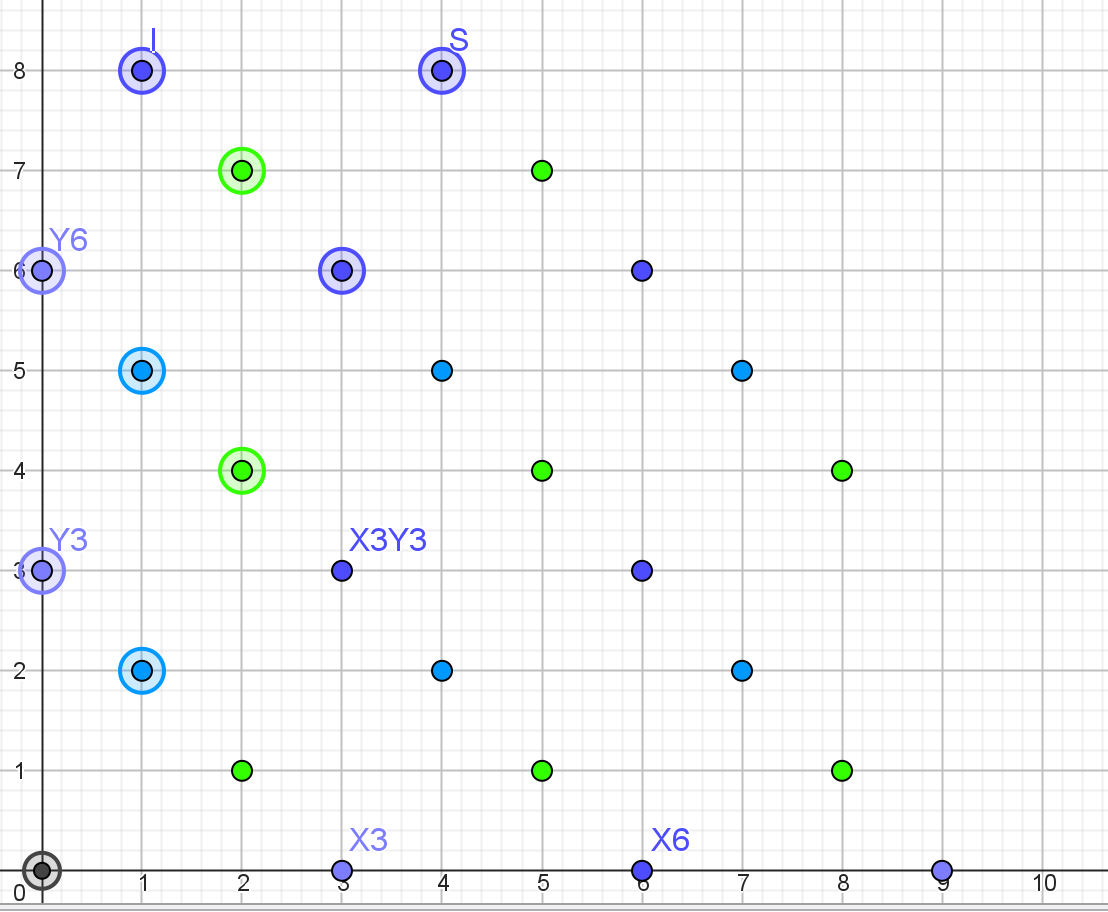
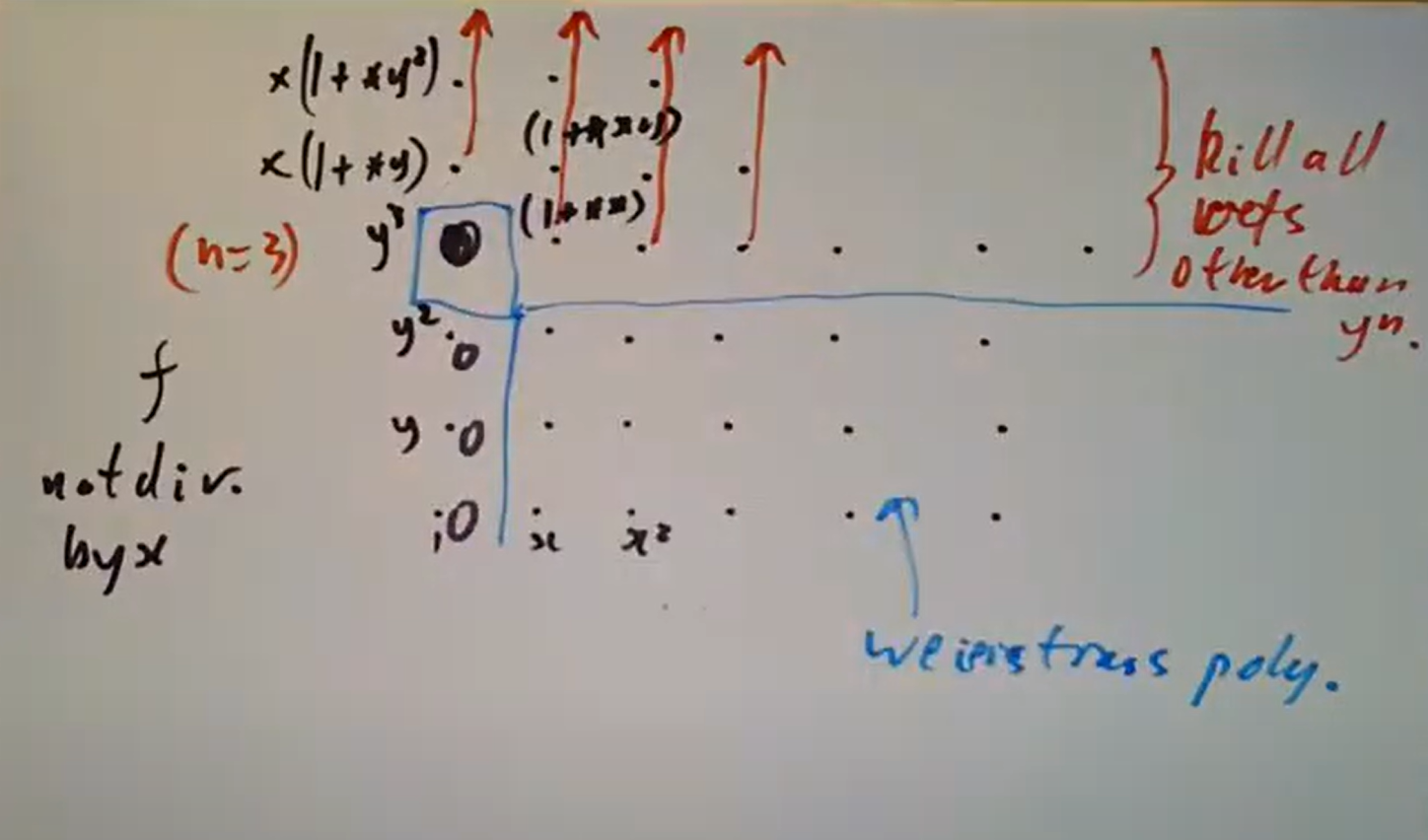 这样下来乘上这些元素的无穷乘积即可消去诸
这样下来乘上这些元素的无穷乘积即可消去诸 
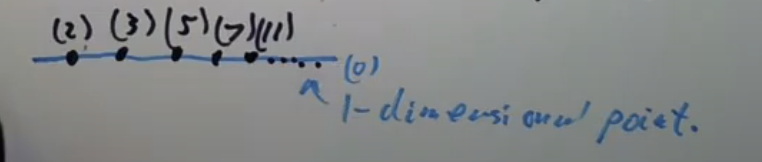


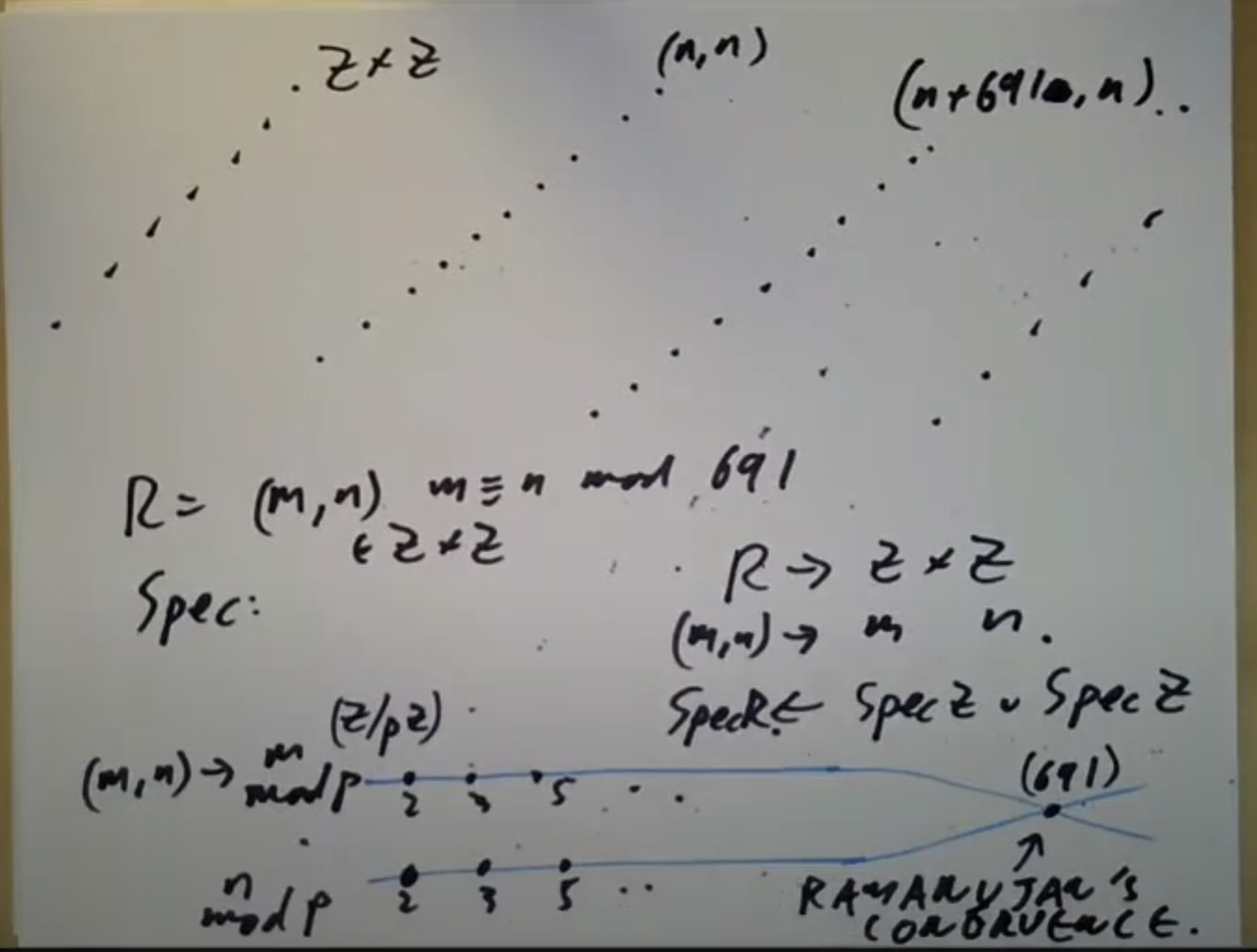 像691这样的素数被称为Eisenstein素数。
像691这样的素数被称为Eisenstein素数。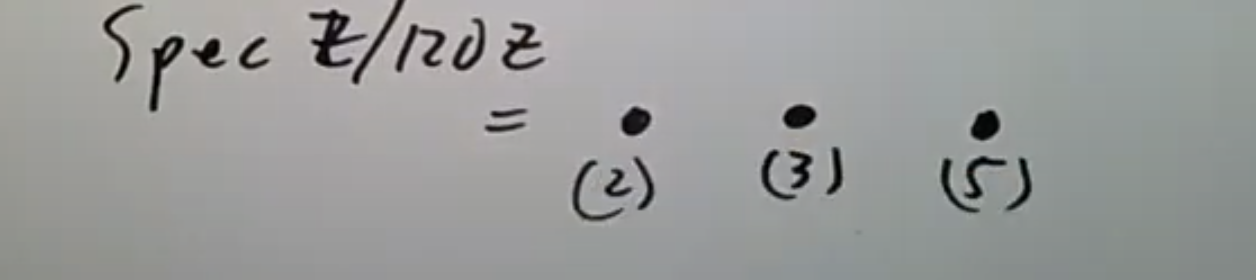

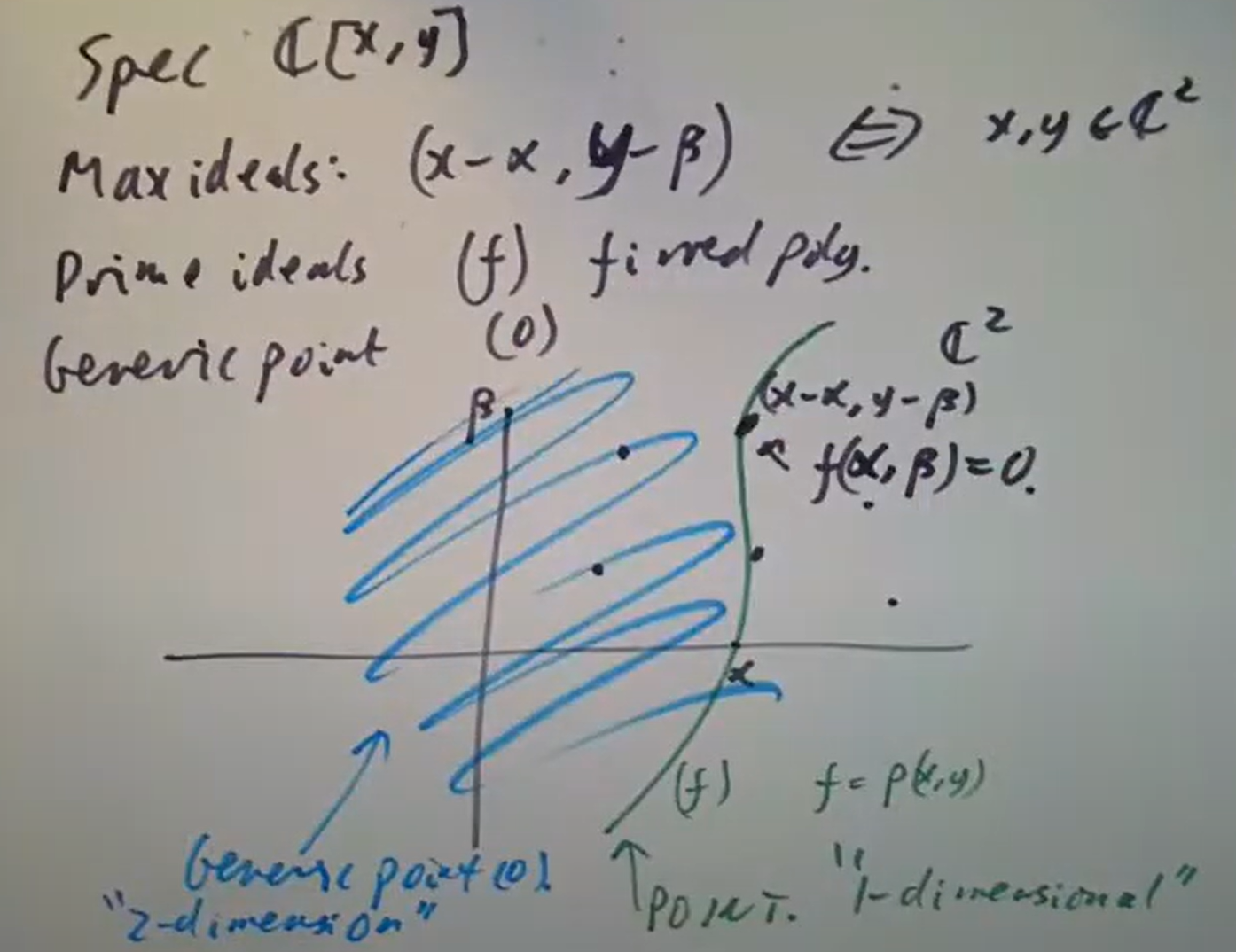
 总共这里有四个不可约分支,对应四个
总共这里有四个不可约分支,对应四个 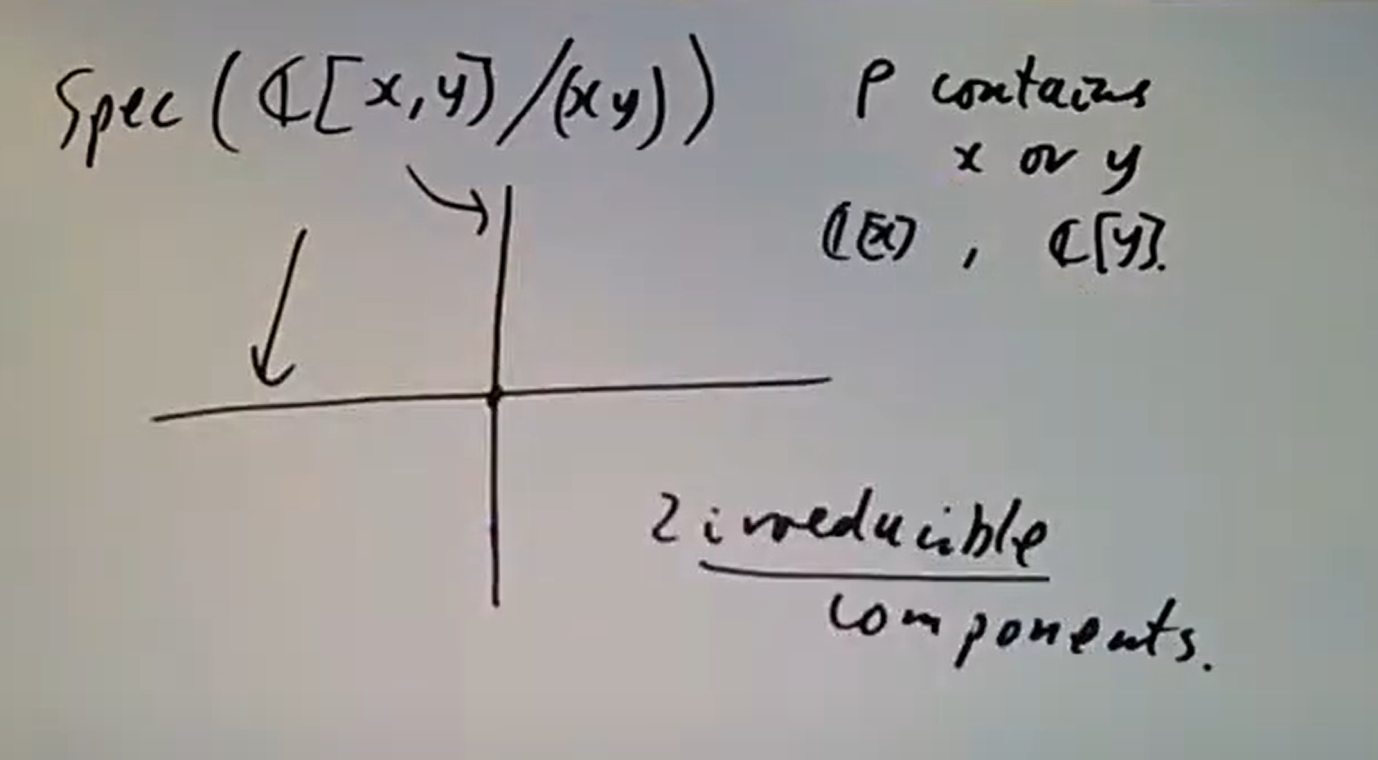
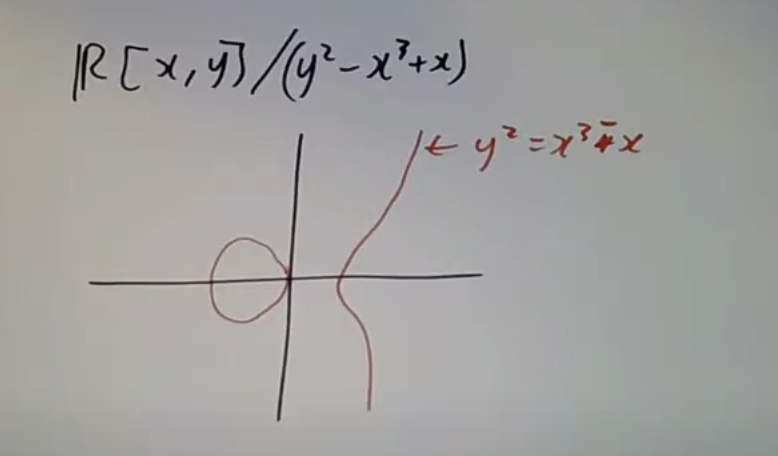
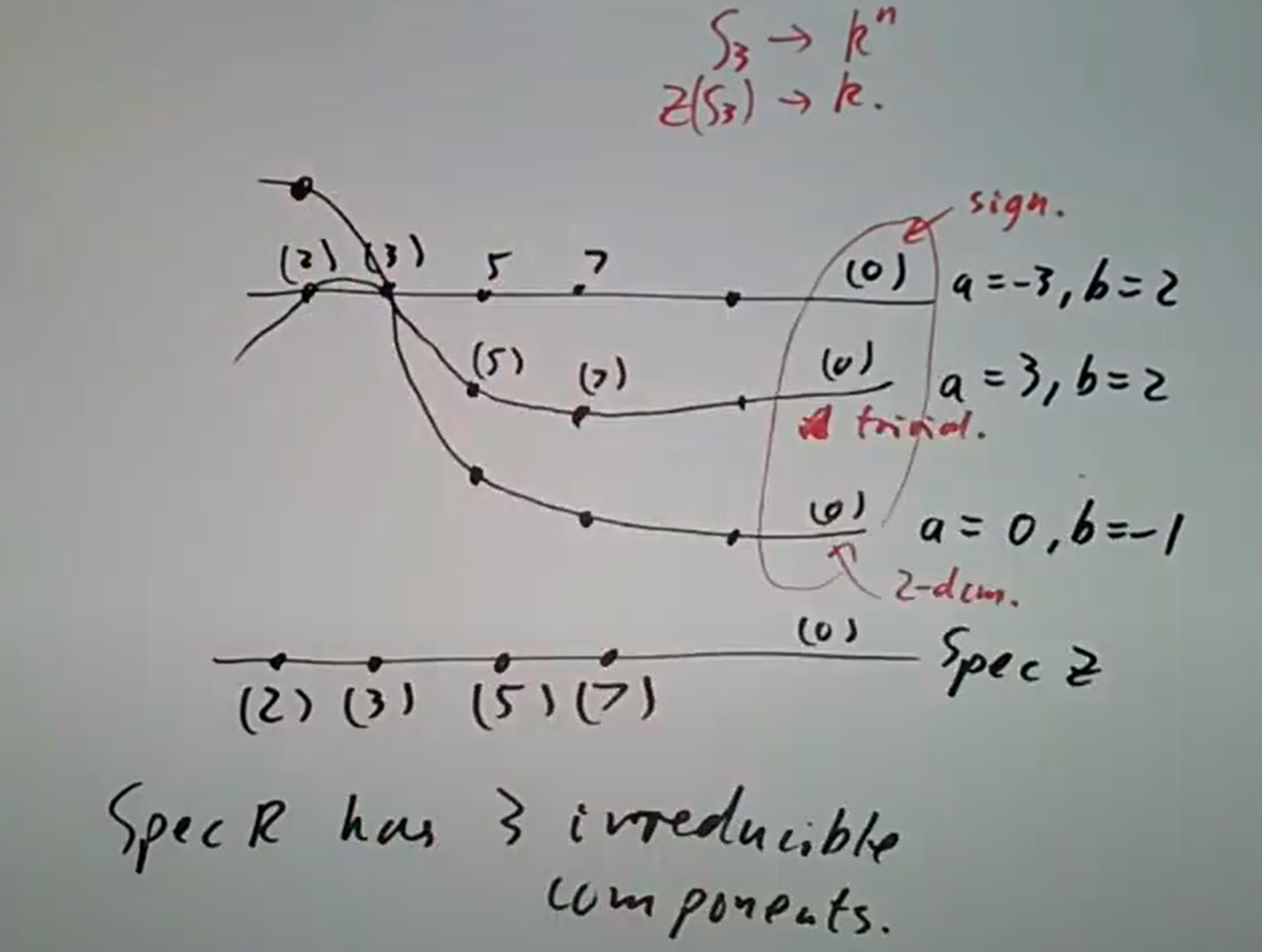 三个不可约分支对应三个
三个不可约分支对应三个 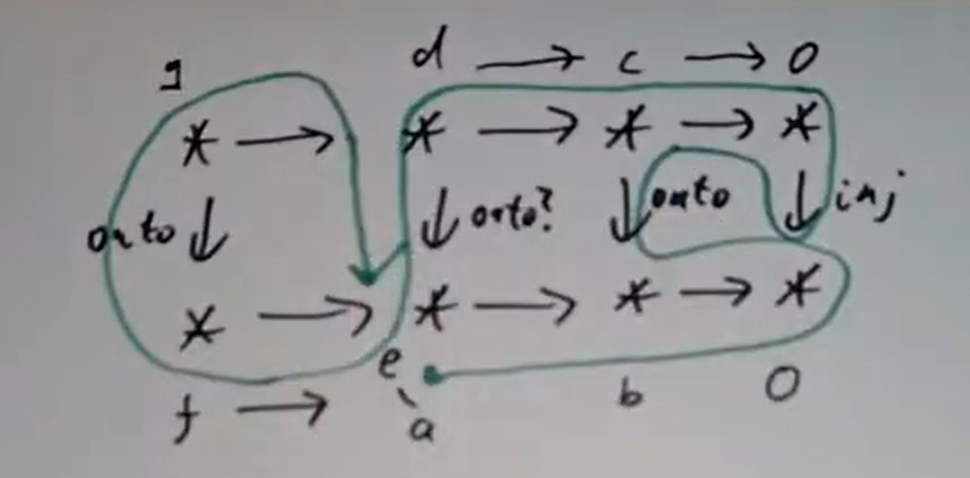 取
取